Data volumes are growing rapidly around the world, and in order to effectively use their immense potential, proper storage and management of information is required. One of the most effective ways to solve this problem is database consolidation. What is it and how to implement it correctly? In this article we’ll look at the ways database consolidation can benefit to you and how to implement it in practice. If you want to optimize your work with data, this article is for you!
Advantages of the consolidation
▍Improved performance
Database consolidation can improve system performance, especially for the organizations that have many different databases. Rather than searching through different databases each time you need any data, consolidation will store it all in one place, reducing access time and speeding up the overall data retrieval and processing process.
▍Simplification of the data management
When you have multiple databases, managing them can be a daunting task. Consolidating all the data into a single database reduces the complexity of the management all the data will be stored in one place.
▍Reduced maintenance costs
Database consolidation reduces maintenance costs due to the fact that the technicians are not involved into the maintenance of several databases, one only. In addition to that, the need for additional updates and modifications is reduced, as all changes will be made to one database only.
▍Improved security
Database consolidation usually increases security because data is more secure when it is stored in one database instead of being scattered across multiple databases. This happens because a single centre controls access to the data and all the changes and events occur in a single system.
▍Improved communication and teamwork
Consolidation of all the data into one database facilitates communication and collaboration between people in an organization significantly. When everyone uses the same database, it makes it easier to share information and work on common projects.
Steps to the database consolidation
In order to organize database consolidation at a high level, you need to follow a few steps:
1) analysing of the existing databases and determining the requirements for a new one. A successful consolidation process requires a comprehensive analysis of the information contained in the various databases to be consolidated. It must be determined what information is stored in the databases, how it is used, and what data can be deleted or merged.
Once the information has been analyzed, the requirements for the new database are to be defined. It is a complex process that involves selecting the most appropriate data structure, how the data is stored and other parameters such as security and scalability.
For example, if publicly available databases are to be consolidated into a more secure database, it is necessary to analyze the data and determine which data should not be accessible to all the users. Determining security requirements will help you to choose the right database structure and set the right restrictions on the access to the information.
This step allows you to take into account all the unique needs and data requirements associated with a particular business process and make database consolidation the most efficient and effective for the specific case.
2) identifying appropriate consolidation technologies and tools. It involves selecting the technology that will make consolidation as efficient and cost-effective as possible.
To do this, you need to explore the various data consolidation tools and technologies available. You can use DBMSs such as Oracle, Microsoft SQL Server or PostgreSQL, or more flexible technologies such as NoSQL databases like MongoDB or Apache Cassandra. Each technology has its advantages and disadvantages.
For example, if your company works with large amounts of structured data, organizing a database based on a relational DBMS may be the most appropriate solution. On the other hand, if your organization works with a large amount of unstructured data, such as logs or social media data, then using NoSQL technologies may be the best choice.
In addition to that, the choice of the appropriate technology depends on the requirements for data redundancy and access speed. Basket building, data segmentation, server virtualization, etc. can be used to solve these problems.
3) designing a new database and testing. At this stage, a new database is created and customized, which will combine all the old databases.
It is important to consider that the design of the new database is intended to solve all the problems that were identified in the first stage of analysis, as well as to define the requirements for the new database.
In the context of testing, all the existing data should be imported into the new database and checked for proper migration. In addition, performance testing of the new database should be performed to ensure that the new database runs quickly and efficiently.
Testing is an integral part of the database consolidation process because it helps to identify problems and errors before the new database will be used.
In addition, this step should include training the staff who will be working with the new database, and ensuring that only designated users with specific permissions have access to the database.
4) data migration and staff training. After successful development and testing of the new database, data migration from the previous databases should be performed. In addition, staff should be trained on the new database and the necessary system settings should be made.
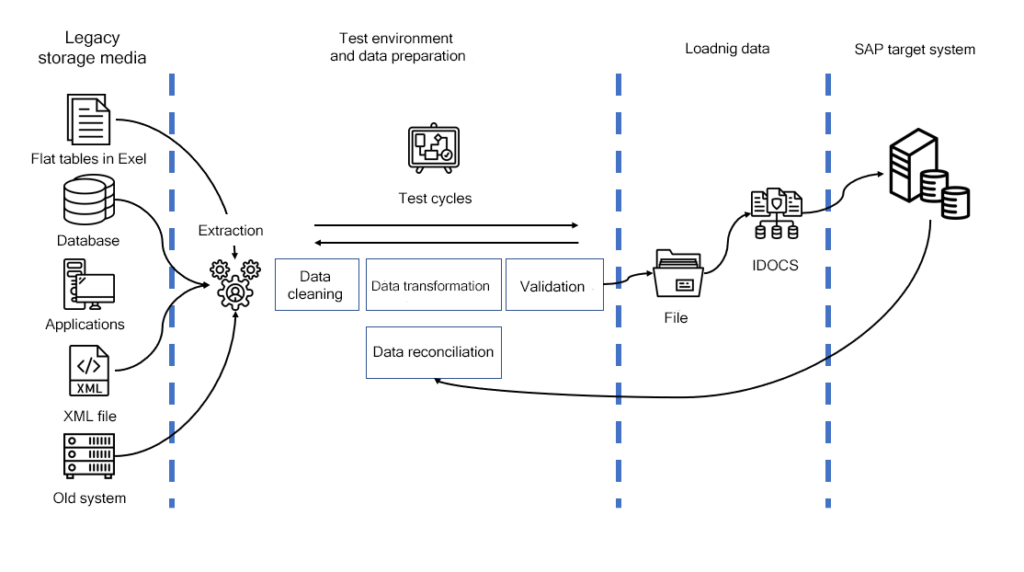
Key consolidation methods
▍ ETL
ETL is a database consolidation method that stands for Extract, Transform, Load.
This method of working with data involves several steps. First of all, the data is extracted from various sources, usually through APIs or data extraction software. Then they are transformed, which may include cleaning, filtering, matching, and merging data from different sources. Finally, the data is loaded into a database where it can be used for analysis and reporting purposes.
An example of using ETL is data processing for an online shop that has multiple data sources such as sales reports, suppliers, warehouses and transport companies. In order to get the overall information and perform analyses, it is necessary to combine these data into one database. With ETL, data can be extracted from data sources, converted into a format suitable for analysis, and loaded into a common shop database.
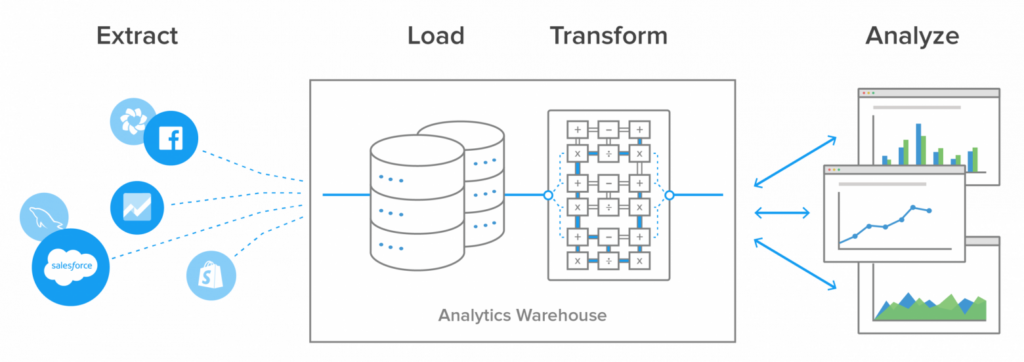
However, the use of ETL can also cause some problems. For example, data extraction and processing can be time-consuming and require extremely powerful hardware. In addition to that, while consolidating large amounts of data, it may be necessary to handle a large number of duplicates, such as records that are in different sources.
Thus, ETL is a method that can be used in order to consolidate data, but it requires careful planning and high performance. While using ETL, it is important to consider the volume of data, the data conversion algorithms and the security requirements at all the stages of the process.
▍Data virtualisation
This is a database consolidation method with the help of which data from different sources can be combined without physically moving or copying it. It is possible due to the usage of a virtual database created from metadata that can refer to and access data from different sources.
One of the main benefits of virtualization is that data can be accessed in a single place, which can simplify data processing and improve data quality. Virtualization can also help to reduce the time spent on data integration and transformation, and improve data security by centrally managing access to data.
An example of using data virtualization in database consolidation might be the following: a large company may have several databases containing customer data. Using virtualization, these databases can be consolidated into a single virtual database that will provide consolidated information on all customers. In doing so, the actual data will each be stored in its own real database and the virtual database will use metadata to access it.
However, when using data virtualization, there can also be some challenges associated with integrating different data sources, as well as security and data access control rules.
▍ Data warehouses
A data warehouse is a database consolidation method that creates a centralized place to store all the data needed for analysis and decision making. It is often used in large companies that have multiple databases located in different locations and storing different information.
One of the advantages of a data warehouse is that it allows you to collect and combine data from different sources, such as internal company systems, cloud services or external data providers. This enables you to get a complete picture of the company and make quick decisions based on this information.
Various tools such as SQL Server, Oracle, Teradata and others can be used to create a data warehouse. The data warehouse can store data types such as text documents, images, audio and video files, and various types of structured data.
A data warehouse can be organized in a three-tier architecture: operational data warehouse (OLTP), data characteristics store (ODS) and data warehouse (Data Warehouse). The operational data warehouse contains current information about business processes, the data characteristics warehouse contains archival information, and the data warehouse provides access to analytical data necessary for decision-making.
A data warehouse can also be built according to different models such as Snowflake, Star or Moonscapes. Each model has its own advantages and disadvantages and can be used depending on the specific needs of the company.
One of the main challenges in creating a data warehouse is to ensure data security as well as optimizing performance. This can be done by using query monitoring and optimization tools, as well as implementing data access policies and auditing.
Using a data warehouse in a database consolidation allows a company to get a consolidated view of its operations, improve management efficiency and make decisions based on complete and accurate information. However, implementation and operation of a data warehouse requires a comprehensive approach and professional knowledge in the field of databases.
Recommendations
In large and multi-user organizations databases become very voluminous and difficult to manage. Improved productivity and more efficient access to information require an optimized structure and a single point of access to the data.
Database consolidation can help organizations to meet this challenge. Merging all data into a single aggregate simplifies the data management process and significantly improves the system performance.
Choosing the right technologies and careful planning are key success factors in database consolidation.
Before you start the data consolidation process, you need to decide what technologies will be used. It can be any combination of technologies, including relational databases, NoSQL `and cloud data warehousing. However, you need to evaluate each technology carefully and select those that suit the needs of the organization.
While choosing the technologies for database consolidation, you need to consider various factors such as data volume, performance and security requirements, and whether there are specific database requirements. For example, relational databases may be better for large and complex databases, while a NoSQL database – for simpler tasks.
Careful planning includes not only the choice of technologies, but also a thorough risk assessment and proper organization of the consolidation process. You need to make sure that there are enough resources (computer hardware, engineering networks and personnel) to implement the plan. In addition to that, you need to define a global project plan and consider the local requirements for each database to be consolidated.
Moreover, it is important to provide backups and data recovery systems in case of unexpected failures. If possible, measures can be implemented to scale the database if needed. Data security should also be ensured, including means of user authentication and authorization, database auditing and monitoring.
Careful planning and selection of the right technologies can help to unlock the potential of database consolidation and minimize the risks of potential negative consequences.
▍Recommendations for maintaining and monitoring of the consolidated database
While monitoring and optimizing a consolidated database it is highly recommended to use software that allows you to monitor performance, analyze queries and identify bottlenecks. For example, you can use database monitoring applications such as SQL Server Management Studio, Oracle Enterprise Manager and others.
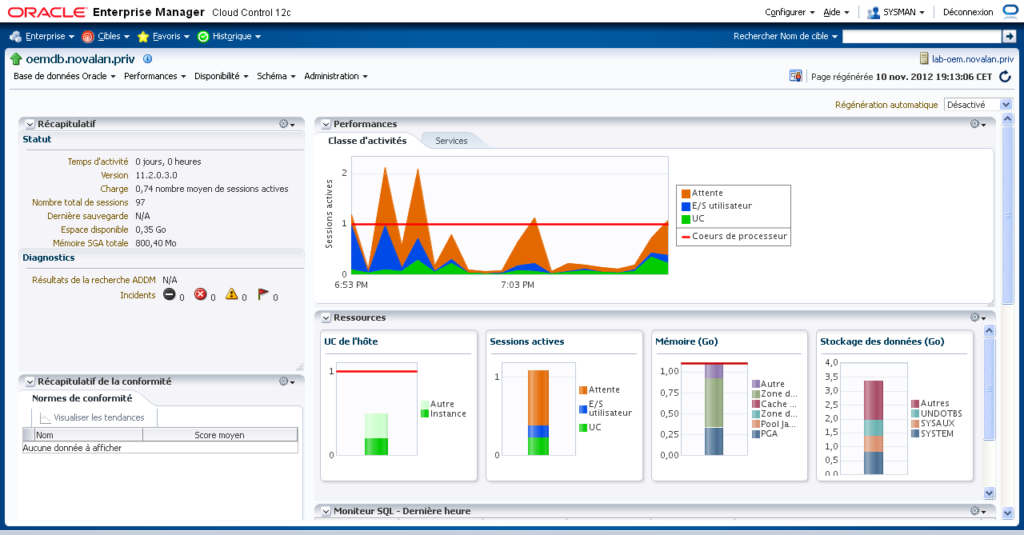
Another important aspect is database support. Various problems may occur while working with the consolidated database such as outages, lack of resources and others. Therefore, it is necessary to have a team of developers and system administrators who will be responsible for the support and maintenance of the consolidated database.
One of the important parts of maintaining and monitoring the consolidated database is regular data backups. This not only protects data from possible loss, but also ensures that the database can be quickly restored in the event of system failures. Backups should be performed daily or more frequently, depending on the criticality of the data.
In addition to that, it is necessary to provide the maximum level of security for the consolidated database. This can be done, for example, by setting passwords for database access, data encryption, user authentication and authorization and other security methods. By applying monitoring, maintenance and security recommendations, it is possible to ensure the efficient use of the consolidated database and to guarantee the integrity and confidentiality of the data.
Example of a task
▍ example N 1
Let’s assume that our airport has several databases that store information about flights, passengers and tickets. These databases have been created by different departments and use different data formats, which makes it difficult to process the information and can lead to serious errors.
Our task is to merge these databases into one in order to to simplify data handling and improve processing accuracy. In order to do this we will create three abstract tables for each database.
- The first table “Flights” will contain information about flights: flight number, departure point, destination, departure and arrival time;
- The second table “Passengers” will store all the data about passengers: name, surname, date of birth, passport number and place of residence.
- The third table “Tickets” will contain information about tickets: ticket number, flight number, passenger name, departure date and price.
We will use SQL and the following steps in order to consolidate the databases:
- Let’s create a new database and call it “Airport Consolidated”.
- For each of the three tables Flights, Passengers and Tickets, we will create a separate table in the Airport Consolidated database with the appropriate fields. For example, the Flights table will have the FlightNumber, DepartureAirport, ArrivalAirport, DepartureTime and ArrivalTime fields.
- For each table from the original databases create queries to sample the data and import the data into the tables in the new database.
- Merge the data from the Tickets table with the Flights and Passengers tables. To do this, we will use the JOIN operator, joining the tables by flight number and passenger name. For example:
SELECT FlightNumber, DepartureAirport, ArrivalAirport, DepartureTime, ArrivalTime, Name, PassportNumber, Price
FROM Flights
JOIN Passengers ON Flights.FlightNumber = Tickets.FlightNumber
JOIN Tickets ON Passengers.Name = Tickets.PassengerName- Save the resulting data to the new Booking table. The table stores the fields:
FlightNumber
DepartureAirport
ArrivalAirport
DepartureTime
ArrivalTime
Name
PassportNumber
PriceLet’s check the data in the new table for duplicates and incorrect data. To do this, use the DISTINCT and WHERE operators.
For example, let’s find all the duplicates by flight number:
SELECT FlightNumber, COUNT(*) FROM Booking GROUP BY FlightNumber HAVING COUNT(*) > 1
- Indexes can be added I order to speed up connections and data selections.
▍ Example N2
There are two databases with information about users: users_db1 and users_db2. It is necessary to make a consolidated users database to which all the data from users_db1 and users_db2 databases will be transferred. It should be taken into account that both databases may have the same user records but at the same time they may have different data. If the data in different records are the same, then you should select the values from users_db1.
- Creation of the users table in the consolidated database:
CREATE TABLE users (
id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50) NOT NULL,
email VARCHAR(50) NOT NULL,
age INT,
gender VARCHAR(10)
);- Retrieving all records from users_db1.
INSERT INTO users (username, email, age, gender)
SELECT username, email, age, gender
FROM users_db1;We need to get the user data from the users_db1 table and add it to the users table. To do this, we use the INSERT INTO command, specify the table name and columns to which we will add records, and then we call SELECT and specify the columns from the users_db1 database.
- Update the existing records in users table from users_db2:
UPDATE users
SET email = users_db2.email,
age = users_db2.age,
gender = users_db2.gender
FROM users_db2
WHERE users.email = users_db2.emailIf the second database users_db2 contains records about the user with the same email, in order to avoid data duplication, we will update the data in users by email from users_db2, and if the data match, we will leave the values from the table users_db1. To do this we use the UPDATE command, in which we specify the table users, in which we will change the records, after SET we specify the columns that will be changed, and then put FROM users_db2 and WHERE conditions to update the data occurred only in users with the same email.
- Insert new records from users_db2 that are not in the users table.
INSERT INTO users (username, email, age, gender)
SELECT username, email, age, gender
FROM users_db2
WHERE email NOT IN (SELECT email FROM users)To add new users the same INSERT INTO and SELECT commands are used, but now we specify the users_db2 database, and the WHERE clause will check if there is already a user with the same email in the users table, there is no need to add a new record.
- Checking the result.
SELECT * FROM users;I order to verify the consolidation results, we can display all the records from the users table using the SELECT command.
Final thoughts
Database consolidation is one of the most important processes in today’s world of information technology. It allows to optimize the use and storage of data, reduce database maintenance costs and increase the efficiency of the enterprise. In addition to that, database consolidation helps to reduce the time to find the necessary data and improve the quality of decisions. However, it is important to consider the risks and challenges that may arise during the consolidation process. Therefore, for the successful implementation of this process, it is necessary to conduct a comprehensive assessment and planning, as well as apply modern methods and technologies to improve database consolidation