Cloud services are resources leased for computing and data storage. A cloud provider offers virtual machines, disks and resources for serverless computing and takes care of the whole range of technical activities for their deployment and support. As far as a Client is concerned, he or she gets not only a resource or a service but also an opportunity to make the scalability more efficient and to optimize the costs of hardware and software. This kind of services may be extremely useful for a great range of tasks but here we would like to single out storage and processing challenges.
Archive storage
Data which is not needed for instant access is often made “cold”. It is deleted from the expensive disk of the main storage platform (DWH or Data Lake) and is transferred to the archive. Technically, this archive can be arranged as an array of storage devices (disks and tapes). A Hadoop cluster also often acts as an archive system: data is stored in HDFS and is available for analysis via various SQL engines.
Object Storage
Cloud providers often offer Object Storage service (or Blob Storage). Their functions are the following:
- data distribution;
- replication;
- hardware encryption;
- replacement of outdated equipment.
Access to the data is granted via REST API. The de facto standard for data access is S3 protocol, which was firstly offered by the Amazon Web Services for its Object Storage, that is why saying S3 often means any object storage (not Amazon only and even not necessarily supporting the S3 protocol).
Tariffication
The main advantage of the clouds for the final consumers is flexible tarrification. Usually a Client pays for the amount of stored data and for the traffic. Both of them have the same measurement unit – gigabytes. It means that it is not necessary to purchase petabyte disk arrays beforehand and pay for their maintenance. To store an on-prem archive we would purchase a storage system large enough to store archives for a year (for example) and subsequently would buy disks increasing the volume every six months or a year. In the cloud we pay only for the data that we store at the moment.
Access to the data
Access to the data stored in the S3 object storage is highly variative. There are the following variants:
- REST API. File system intuitive methods are implemented: return an object list, put a new object, get an object, copy, delete. However some providers support S3 select as well: if files are stored in json, csv or parquet format, simplified SQL with aggregations and filtering is applicable;
- FUSE. Object storage can be mounted to a machine as a file system and then it will be possible to interact with it in the same way as with disks;
- Client applications such as S3cmd or AWS (the latter’s functionality is broader than interaction with S3). Commands put, get, ls, cp and so on are implemented;
- Many MPP solutions have S3 connectors. For example, in Greenplum you can create an external table with data stored in S3; Hadoop can work with S3 in the same way as with HDFS, and, accordingly, sql engines (Hive, Impala, Trino and others) can work with structured data in S3.
Managed services
MPP
One of the MPP systems, often deployed on-prem, can be chosen as the platform for DWH or Data Lake. The cloud provider not only provides capacities for these systems but takes but also:
- automatic configuration;
- support of monitoring tools;
- backup and recovery;
- traffic encryption.
Various MPPs can be offered as a service in the cloud. A cloud provider can provide its solution as a service (e.g., Oracle Cloud Infrastructure provides Oracle Exadata). But first of all we would like to point out the following solutions – Hadoop и Greenplum.
Hadoop
Apache Hadoop ecosystem products are suitable for building Data Lake and are widely used on-prem. Often used components are the following:
- HDFS – for hot storage;
- Hive, Impala, SparkSQL – for data access and ELT;
- Spark – for ELT and analytics;
- Sqoop – for integration with data bases.
One of the main advantages of Hadoop is its horizontal scalability. It can be effectively used in the cloud. A separate data cluster is deployed for HDFS, which is supposed to be expanded only in case of necessity. As far the computational tasks, running MapReduce and Spark-jobs are concerned, compute clusters can be deployed. Their size can be easily enlarged or reduced.
Cluster scaling can be automated and based on the percentage of CPU cores utilization or the number of active YARN containers. Temporary clasters can also be used for showcases. Such scalability allows saving on deleted nodes. In addition to that, this approach increases the “boldness” of ad-hoc analytics: if for some reasons it is necessary to buy hardware for the data center of your organization, the analyst will have to coordinate the budget that is a very long and complicated process. If for the same analysis it is necessary to rent even a very powerful spark cluster for a week, the coordination will be much easier.
Greenplum
MPP-systems based on PostgreSQL are used widely, including in the cloud technologies. Greenplum, Arenadata DB, ApsaraDB AnalyticDB for PostgreSQL are the best examples. A provider solves maintenance tasks not only with the help of a standard set of utilities, but also by editing the product code, as Greenplum is an actively developing open-source solution.
What sets Greenplum apart from the Hadoop ecosystem is its support for ACID transactions. It goes without saying that using Greenplum’s ACID mechanisms requires careful approaches to data updates. But it is difficult to do without it in complex storage systems where one and the same table can be used simultaneously as a data receiver in one process and as a data source in another.
Unlike Hadoop in Greenplum we can’t just disable half of the segment hosts and expect to reduce performance only. No, such kind of actions will lead to data inaccessibility. But expanding a Greenplum cluster in the cloud still looks like a simpler procedure than on-prem. To extend a cluster engineers need to do the following:
- remove backup (this should be a simple, quick and regular procedure in the cloud);
- allocate additional hosts to the cluster;
- deploy the backup on the updated cluster.
Additional services
Data warehouse cannot exist in a vacuum: it will simply be useless then. I will briefly touch upon the additional tools that clouds can provide:
- services for logging with automatic log rotation and access control;
- DBMS like MySQL or PostgreSQL for metadata storage. Everything is as usual in the cloud: backup, automatic maintenance, fault tolerance etc.;
- DBMS for the presentation layer such as ClickHouse;
- visualization tools from a provider;
- services for process orchestration;
- integration tools;
- Data Governance tools;
- virtual machines to install the software that is missing.
Cloud storage
To take full advantage of the cloud approach in building a DWH, an MPP system should meet multiple requirements:
- provide flexible access differentiation;
- scale compute capacities and use them efficiently;
- have a developed SQL dialect;
- “cool down” old data;
- store backups cheaply and provide quick access to them;
- update almost invisibly for a user and be available 24/7;
- encrypt data and traffic.
None of the MPP systems listed above meets this set of requirements. That’s why there are special solutions for the use in clouds. I will talk about two of them: Snowflake and Databricks.
Snowflake
Snowflake is neither a managed service in any of the clouds, nor a software that can be deployed under a license. It is a standalone service that allows the user to choose a regional data center and a cloud provider to host the infrastructure: Microsoft Azure, Amazon Web Services or Google Cloud. A user can download and store data and access it via SQL – via a web interface or a JDBC/ ODBC driver.
Snowflake separates data storage and processing. The client pays for storage and for data processing processing, as well as for network traffic.
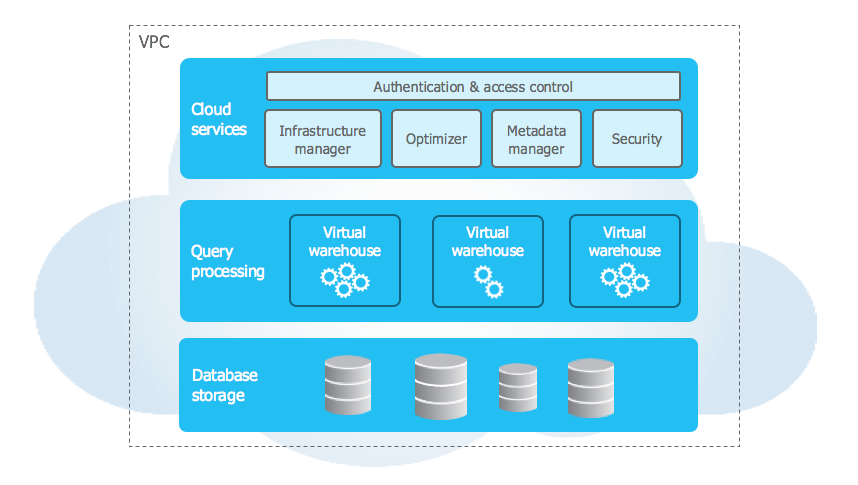
The method of data storage is not disclosed. Basing on the official documentation we know that data is divided into small portions – micropartitions. You can set a “clustering key” and expect that strings with different key values will end up in different micropartitions. Deleted data is stored for some time and can be accessed with the help of so-called time travel: you can select previously deleted data using a simple SQL query.
Except for the clustering key and time travel, a user has no any influence on data storage: he or she does not set the compression algorithm, the size of the micropartition, the storage location (network or local disk, SSD or HDD, S3 or local system) and so on. The more space the data will take up, the more money the client will pay – and this is despite the fact that compression works decently and is comparable to well-known compression methods (gzip, zstd or zlib). Storage is charged per gigabyte. ACID-transactions are provided.
Data processing is performed on separate compute-instances which in Snowflake terminology are called Virtual Warehouse (VWH). VWHs are differentiated by capacity and are graduated like T-shirts: they come in sizes S, M, L, XL and so on. Each successive size is twice as expensive as the previous one with the assumption that it is twice as fast to fulfill the same request.
VWHs are billed by minutes, each of them is turned off by default after 10 minutes of idle time and turned on instantly on demand. A user does not know which machines are used for each VWH, but an online execution profile is built for each SQL query with the progress of each logical step. If any of the steps crashes, e.g. due to insufficient resources, the VWH will simply restart it.
Snowflake is a rather closed and opaque service in terms of implementation. However, the experience of using it shows that it is a convenient and reliable tool with flexible pricing.
Databricks
Another cloud-oriented platform is Databricks. It is much more open than Snowflake. Databricks is provided as a service in the marketplaces of the most popular cloud providers: Microsoft Azure, Amazon Web Services and Google Cloud. The services are the following:
- Delta lake – a data storage layer based on open formats;
- Data Engineering – an ETL tool;
- Databricks SQL – serverless-SQL (can be compared to VWH in Snowflake);
- Unity Catalog – a solution for Data Governance;
- Delta Sharing – service for flexible data access management;
- services for machine learning and Data Science.

How to choose the right cloud technology?
Let’s assume that your organization has decided to move some of its DWH infrastructure to the cloud. How will you choose a provider and what facts should you consider? In our opinion, there are a number of questions that need to be addressed to your potential provider in order to make an effective investment in cloud-based big data storage solutions:
- Variability of managed services. Do the provided services cover all your needs? How do the provider’s development plans relate to yours? If you have been dreaming of a neat and accurate DG-tool for a long time, and a provider has just presented its development in Preview, this is a reason to take a closer look at his solution;
- Location of cloud data centers. Even without considering legal restrictions an overseas cloud may not be a good idea. Data migration will likely require a dedicated channel from your organization’s data centers to the cloud data centers. The cost will depend on the distance;
- A number of resources at a provider’s disposal. DWH tasks are highly loaded, and it’s worth making sure a provider will provide you with the computing power you really need;
- What SLAs does the support provide?
- A portfolio of projects successfully completed by other Clients. Which systems proceeded into production and which remained in the pilot stage?
- How stable are the tools you would like to use? It is worthwhile to refer to the experience of other customers and, perhaps, to conduct a pilot project.
I hope that the article was useful for you. If you have any questions please feel free to ask me, I will be glad to discuss them with you!
Mr. Dmitry Morozov, DWH architect at GlowByte, has been engaged in data warehouses for 6 years and have already tried some of these cloud projects. In this article he will tell you about some cloud solutions which are highly recommended for big data storage and will point out some issues which will help you to choose the best option. This article is based on his personal experience, it may be interesting for the developers and data-engineers as well as for the managers who are in charge of corporate big data infrastructure and are looking for the most efficient opportunities to make it more scalable.