Often, in the reviews of the database types, there is information about relational and “other” types, “NoSQL” etc. or the most basic types of DBMSs (databases), the rare ones are not mentioned t all. In this article we will try to describe all the types of the databases and give examples of the specific implementations. Of course, the article does not pretend to be all-embracing, databases can be classified in different ways, including types of optimal load, etc. Moreover, all the types of the databases will be described briefly. But we really hope that the article will give basic understanding of the DBMS types as well as of the principles of their operation.
In this article we are going to talk about the following types of the databases:
- Relational
- Key-value
- Document-oriented
- Time series databases
- Graph Databases
- Search Engines
- Object-oriented databases
- RDF (Resource Description Framework)
- Wide Column Stores
- Multimodal DBMS
- Native XML DBMS
- GEO/GIS (spatial) and specialized DBMSs
- Event DBMS (state transition databases)
- Content DBMSs
- Navigational DBMSs
- Vector databases
Let’s start with the most common type – relational DBMSs.
Relational DBs
The most well-known relational databases are Open Source projects PostgreSQL, MySQL and SQLite, as well as proprietary solutions such as Oracle, Microsoft SQL Server and IBM Db2Relational.
The essence of relational databases consists in data storage in the linked tables:
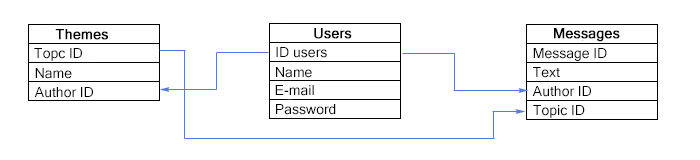
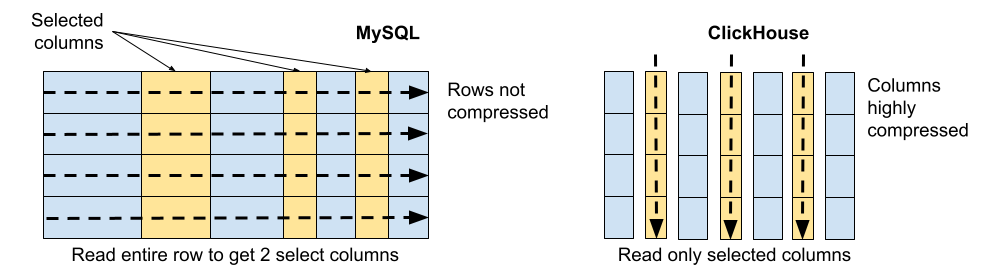
It is also worth saying that the relational databases come with row-based (PostgreSQL) and column-based (ClickHouse, Vertica) data storage. Column databases are better for analytics purposes, while row orientation database is better for transactional workloads.
Relational DBMSs are the most common type of the databases. The table with more than 150 relational variants is given below. The source of this list is a special site-agregator.
Full list of 166 relational DBMSs
- Oracle – relational, multimodal
- MySQL – relational, multimodal
- Microsoft SQL Server – relational, multimodal
- PostgreSQL – relational, multimodal
- IBM Db2Relational – multimodal
- Microsoft Access – relational
- SQLite – relational
- Snowflake – relational
- MariaDB – relational, multimodal
- Microsoft Azure SQL Database – relational, multimodal
- Hive – relational
- Databricks – multimodal
- Teradata – relational, multimodal
- Google BigQuery – relational
- FileMaker – relational
- SAP HANA – relational, multimodal
- SAP Adaptive Server – relational
- Microsoft Azure Synapse Analytics – relational
- Firebird – relational
- Informix – relational, multimodal
- Amazon Redshift – relational
- Impala – relational, multimodal
- Spark SQL – relational
- ClickHouse – relational, multimodal
- Netezza – relational
- Vertica – relational
- Presto – relational
- dBASE – relational
- Apache Flink – relational
- Greenplum – relational, multimodal
- Amazon Aurora – relational, multimodal
- H2 – relational, multimodal
- Oracle Essbase – relational
- Microsoft Azure Data Explorer – relational, multimodal
- Microsoft Azure Data Explorer – relational, multimodal
- CockroachDB – relational
- Derby – relational
- Interbase – relational
- Trino – relational, multimodal
- SingleStore – relational, multimodal
- SAP SQL Anywhere – relational
- Ingres – relational
- HyperSQL – relational
- Ignite – multimodal
- SAP IQ – relational
- Virtuoso – multimodal
- OpenEdge – relational
- Oracle NoSQL – multimodal
- Google Cloud Spanner – relational
- YugabyteDB – relational, multimodal
- MaxDB -relational
- TiDB – relational, multimodal
- Apache Druid – multimodal
- InterSystems Caché – multimodal
- InterSystems IRIS – multimodal
- DuckDB – relational
- SAP Advantage Database Server – relational
- HEAVY.AI – relational, multimodal
- 4D – relational
- Percona Server for MySQL – relational
- EDB Postgres – relational
- Apache Drill – multimodal
- EXASOL – relational
- Apache Phoenix – relational
- Citus – relational, multimodal
- Datomic – relational
- Empress – relational
- GridGain – multimodal
- OceanBase – relational, multimodal
- MonetDB – relational, multimodal
- VoltDB – relational
- Tibero – relational
- TimesTen – relational
- IBM Db2 warehouse -relational
- SQLBase – relational
- Firebolt – relational
- Fauna – multimodal
- mSQL – relational
- MatrixOne – relational
- DataEase – relational
- Oracle Rdb – relational
- Altibase – relational
- PlanetScale – relational, multimodal
- NonStop SQL – relational
- Cubrid – relational
- Infobright – relational
- Apache Kylin – relational
- GBase – relational
- Apache HAWQ – relational
- NuoDB – relational
- Dolt – relational, multimodal
- solidDB – relational
- FoundationDB – multimodal
- 1010data – relational
- openGauss – relational, multimodal
- HFSQL – relational
- Actian Vector – relational
- SQL.JS -relational
- OpenBase – relational
- Vitess – relational, multimodal
- Kognitio – relational
- StarRocks – relational
- TDSQL for MySQL – relational, multimodal
- DBISAM – relational
- FrontBase – relational
- TypeDB -multimodal
- NexusDB – relational
- Datacom/DB – relational
- Kinetica – relational, multimodal
- eXtremeDB – multimodal
- ScaleArc – relational
- VistaDB – relational
- Yellowbrick – relational
- Splice Machine – relational
- Postgres-XL – relational, multimodal
- Alibaba Cloud MaxCompute – relational
- AlaSQL – multimodal
- Apache Pinot – relational
- Alibaba Cloud AnalyticDB for MySQL – relational, multimodal
- SQream DB – relational
- Sequoiadb – multimodal
- Kingbase – relational, multimodal
- Trafodion – relational
- R:BASE – relational
- Apache Doris – relational
- Transbase – relational
- Lovefield – relational
- Raima Database Manager – multimodal
- Alibaba Cloud AnalyticDB for PostgreSQL – relational
- Tajo – relational
- Mimer SQL – relational
- Kyligence Enterprise – relational
- YDB – multimodal
- Databend – relational
- Actian PSQL – relational
- Alibaba Cloud ApsaraDB for PolarDB – relational
- Brytlyt – relational
- XtremeData – relational
- TransLattice – relational
- ElevateDB – relational
- Comdb2 – relational
- Linter – relational, multimodal
- AntDB – relational
- FeatureBase – relational
- LeanXcale – multimodel
- PipelineDB – relational
- GeoSpock – relational, multimodal
- Faircom DB – multimodal
- Tibco ComputeDB – relational
- Valentina Server – relational
- PieCloudDB -relational
- BigObject – relational
- Edge Intelligence – relational
- Fujitsu Enterprise Postgres – relational, multimodal
- EsgynDB – relational
- Transwarp KunDB – relational
- JethroData – relational
- MyScale – multimodal
- OushuDB – relational
- AgensGraph – multimodal
- SmallSQL – relational
- ActorDB – relational
- DaggerDB – relational
- EdgelessDB – relational
- K-DB – relational
- Sadas Engine – relational
Among the “domestic” players we can highlight the following:
- Postgres Pro – PostgreSQL finalized for corporate tasks;
- Jatoba – similar to variant mentioned above as it is based on PostgreSQL;
- Quantum Hybrid – one more PostgreSQL variant;
- Red – a DBMS based on Interbase/Firebird;
- ProximaBD – based on PostgreSQL;
- Arenadata DB – enterprise solution based on Greenplum;
- YDB – serverless solution by the Yandex company. This is an Open Source product which is available for on-premise installations and as a managed service with dedicated/serverless consumption model.
Relational databases cover a wide range of tasks: from transactional databases to analytical ones, but they are not a “silver bullet” for all the tasks. Consider other types of the databases as well.
Key-value DBs
Key-value database type is designed to perform fast, almost instantaneous queries for such tasks as cache, balance display etc. The high speed is realized due to the data storage in accordance with the key-value principle, and in most cases it is effected by operations in RAM.
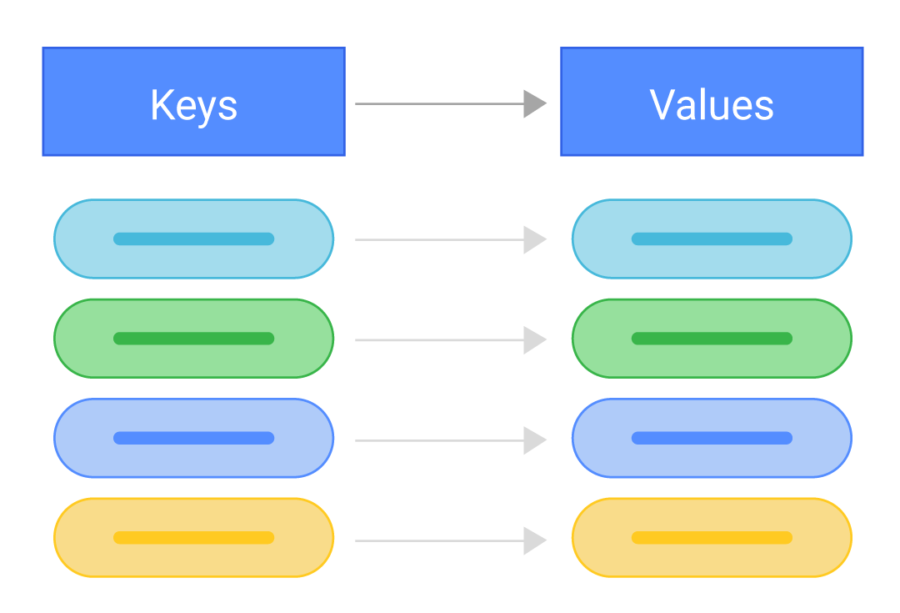
Dictionaries contain a collection of objects or records; objects contain many different fields, containing data (each of them). Records are stored and retrieved by using a key that uniquely identifies the record and is used for fast data retrieval.
The main purpose is to speed up data mapping for the end users and reduce loads, including I/O on organizations’ infrastructure.
The most well-known and widely used Key-Value solutions are Redis and Memcached.
The full list of 72 Key-Value DBMSs is given below:
- Redis – Key-value, multimodal
- Amazon DynamoDB – multimodal
- Microsoft Azure Cosmos DB – multimodal
- Memcached – Key-value
- etcd – Key-value
- Hazelcast – Key-value, multimodal
- Aerospike – multimodal
- Ehcache – Key-value
- Riak KV – Key-value
- Ignite – multimodal
- OrientDB – multimodal
- Google Cloud Bigtable – multimodal
- GemFire – Key-value, multimodal
- ArangoDB – multimodal
- Infinispan – Key-value
- Oracle NoSQL – multimodal
- RocksDB Key-value
- Oracle Berkeley DB – multimodal
- InterSystems Caché – multimodal
- InterSystems IRIS – multimodal
- LevelDB – Key-value
- LMDB – Key-value
- Geode – Key-value
- Amazon SimpleDB – Key-value
- Geode – Key-value
- Amazon SimpleDB – Key-value
- Oracle Coherence – Key-value
- GridGain – multimodal
- Tarantool – Key-value, multimodal
- GT.M – Key-value
- ZODB – Key-value
- FoudationDB – multimodal
- NCache – Key-value
- WebSphere eXtreme Scale – Key-value
- Hibari – Key-value
- MapDB – Key-value
- BoltDB – Key-value
- Graph Engine – multimodal
- Scalaris – Key-value
- KeyDB – Key-value
- Project Voldemort – Key-value
- Upscaledb – Key-value
- Cloudflare Workers KV – Key-value
- Elliptics – Key-value
- Tokyo – Tyrant – Key-value
- LeanXcale – multimodal
- Immudb – Key-value, multimodal
- STSdb – Key-value
- TomP2P – Key-value
- ArcadeDB – multimodal
- Speedb – Key-value
- Faircom DB – multimodal
- Kyoto Tycoon – Key-value
- Skytable – Key-value
- HyperLevelDB – Key-value
- YTsaurus – multimodal
- InfinityDB – Key-value
- Tigris – multimodal
- Badger – Key – value
- Dragonfly – Key – value
- LedisDB – Key-value
- TerarkDB – Key-value
- Cachelot.io – Key-value
- ScaleOut StateServer – Key-value
- JaguarDB – Key-value
- Resin Cache – Key-value
- Faircom EDGE – multimodal
- SwayDB – Key-value
- BergDB – Key-value
- CortexDB – multimodal
- Helium – Key-value
- Tkrzw – Key-value
Among the domestic DBMSs firsr of all we should highlight Tarantool, distributed under the Simplified BSD license, it has a separate version for large corporate clients. Tarantool implements a hybrid data schema: key-value, document-oriented, relational and spatial.
Document-oriented DBs
If you need to store a lot of files or documents and you don’t want to think about storage structure, hierarchy, relationships etc. we suggest choosing one of the document-oriented databases. The main advantage is the wide scalability.
Document-oriented databases are created for the hierarchical data structures (documents) storage. The basis of document-oriented DBMSs are document storages with a tree or forest structure. Trees start from the root node and may contain several internal and leaf nodes. Leaf nodes contain the data, which are entered into the indexes while adding a document; this makes it possible to find the path to the searched data even with a rather complex structure. Unlike the key-value type storages, the selection on the request to the document storage can contain parts of a large number of documents without full loading of these documents into the RAM.
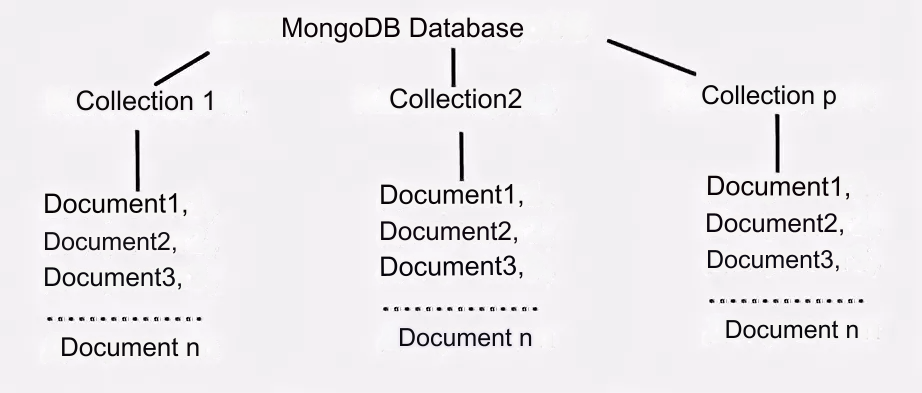
The most popular document-oriented database is MongoDB.
Full list of 56 document-oriented database solutions is given below:
- MongoDB – document-oriented, multimodal
- Amazon DynamoDB – multimodal
- Databricks – multimodal
- Microsoft Azure Cosmos DB – multimodal
- Couchbase – document-oriented, multimodal
- Firebase Realtime Database – document-oriented
- CouchDB – document-oriented, multimodal
- Google Cloud Firestore – document-oriented
- MarkLogic – multimodal
- Realm – document-oriented
- Aerospike – multimodal
- Google Cloud Datastore – document-oriented
- Virtuoso – multimodal
- OrientDB – multimodal
- ArangoDB – multimodal
- RavenDB – document-oriented, multimodal
- Oracle NoSQL – multimodal
- IBM Cloudant – document-oriented
- RethinkDB – document-oriented, multimodal
- InterSystems IRIS – multimodal
- PouchDB – document-oriented
- CloudKit – document-oriented
- Apache Drill – multimodal
- Amazon DocumentDB – document-oriented
- Mnesia – document-oriented
- LiteDB – document-oriented
- Fauna – multimodal
- Datameer – document-oriented
- GigaSpaces – multimodal
- FoundationDB – multimodal
- AllegroGraph – multimodal
- HPE Ezmeral Data Fabric – multimodal
- CrateDB – multimodal
- LokiJS – document-oriented
- BigchainDB – document-oriented
- AlaSQL – multimodal
- SurrealDB – multimodal
- Sequoiadb – multimodal
- Percona Server for MongoDB – document-oriented
- HarperDB – document-oriented
- EJDB – document-oriented
- YDB – multimodal
- ArcadeDB – multimodal
- Bangdb – multimodal
- XTDB – document-oriented
- YTsaurus – multimodal
- OrigoDB – multimodal
- WhiteDB – document-oriented
- ToroDB – document-oriented
- SenseiDB – document-oriented
- Acebase – document-oriented
- iBoxDB – document-oriented
- RaptorDB – document-oriented
- NosDB – document-oriented
- CortexDB – multimodal
- JasDB – document-oriented
Among the domestic solutions, the Yenisei DBMS can be referred to the document-oriented databases.
And within one of the modalities, YDB and YTsaurus can be referred to such databases as well.
Time-series DBs
If you have time-ordered or time-stamped data, such as metrics from infrastructure or sensor data, it may be reasonable to use one of the time series databases.
General characteristics of the time-series databases:
- Time-series data are always collected over a period of time;
- Data from workloads are new and are recorded as inserts. Existing data are not updated by replacement;
- When data are written, they are automatically assigned to the last time interval.
Time-series databases are often used to monitor various metrics (CPU utilization, sensor performance etc.).
The most popular time-series databases are Prometheus, InflubDB, Graphite.
Full list of 43 time-series DBMSs is given below:
| 1. | InfluxDB | Time Series, multimodal |
| 2. | Kdb | multimodal |
| 3. | Prometheus | Time Series |
| 4. | Graphite | Time Series |
| 5. | TimescaleDB | Time Series, multimodal |
| 6. | DolphinDB | Time Series, multimodal |
| 7. | RRDtool | Time Series |
| 8. | Apache Druid | multimodal |
| 9. | TDengine | Time Series, multimodal |
| 10. | QuestDB | Time Series, multimodal |
| 11. | OpenTSDB | Time Series |
| 12. | GridDB | Time Series, multimodal |
| 13. | Fauna | multimodal |
| 14. | VictoriaMetrics | Time Series |
| 15. | Amazon Timestream | Time Series |
| 16. | M3DB | Time Series |
| 17. | Heroic | Time Series |
| 18. | eXtremeDB | multimodal |
| 19. | CrateDB | multimodal |
| 20. | Apache IoTDB | Time Series |
| 21. | KairosDB | Time Series |
| 22. | ITTIA | Time Series,multimodal |
| 23. | Raima Database Manager | multimodal |
| 24. | Axibase | Time Series |
| 25. | Riak TS | Time Series |
| 26. | Machbase | Time Series |
| 27. | CnosDB | Time Series |
| 28. | ArcadeDB | multimodal |
| 29. | Bangdb | multimodal |
| 30. | IRONdb | Time Series |
| 31. | Quasardb | Time Series |
| 32. | SiteWhere | Time Series |
| 33. | NSDb | Time Series |
| 34. | Alibaba Cloud TSDB | Time Series |
| 35. | IBM Db2 Event Store | multimodal |
| 36. | Tigris | multimodal |
| 37. | GreptimeDB | Time Series |
| 38. | Hawkular Metrics | Time Series |
| 39. | SiriDB | Time Series |
| 40. | Blueflood | Time Series |
| 41. | Warp 10 | Time Series |
| 42. | Yanza | Time Series |
| 43. | Newts | Time Series |
Graph DBs
If you need to analyze data relationships, their connections or just simplify queries with Join, it makes sense to use graph databases.
Data and their relationships are represented as vertices and edges of the graph, respectively.
Thus you can easily represent money transfers (to identify various fraudulent schemes), social network connections and the graph of communication between mobile network operators.
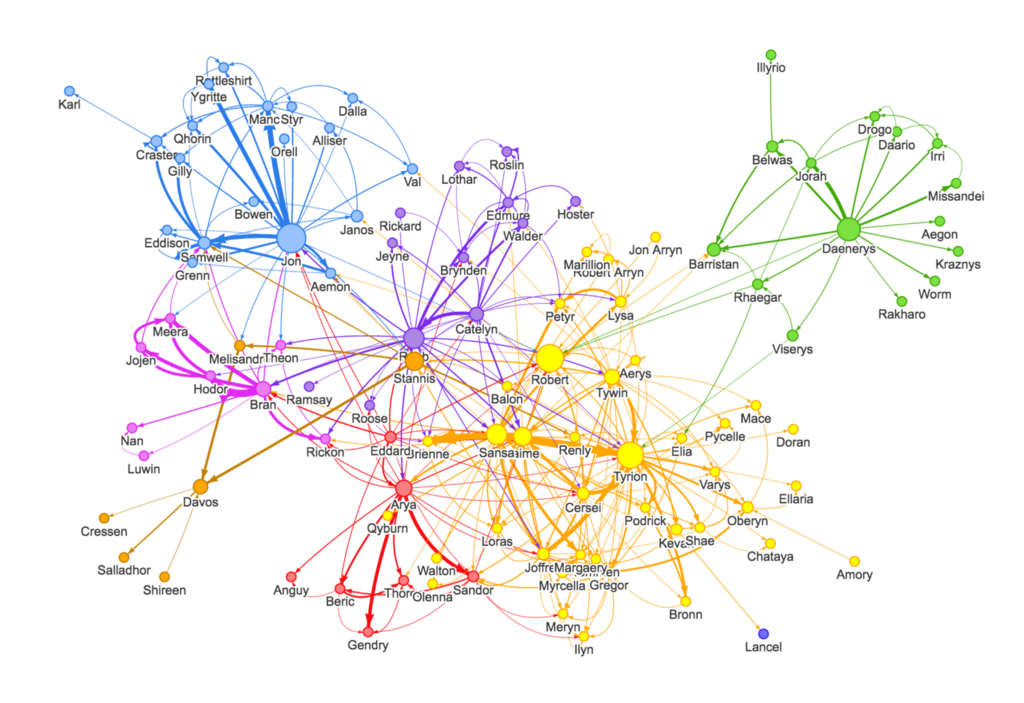
Graph databases are usually used in the financial sphere in order to detect various fraudulent schemes, but they also will be convenient for any other task where it is necessary to work with relations of the objects.
The most well-known Open Source solution is Neo4J, but there are a number of other high-quality alternatives.
Full list of 39 graph databases is given below:
| 1. | Neo4j | graph |
| 2. | Microsoft Azure Cosmos DB | multimodal |
| 3. | Virtuoso | multimodal |
| 4. | OrientDB | multimodal |
| 5 . | ArangoDB | multimodal |
| 6. | Memgraph | graph |
| 7. | GraphDB | multimodal |
| 8. | Amazon Neptune | multimodal |
| 9. | JanusGraph | graph |
| 10. | Stardog | multimodal |
| 11. | NebulaGraph | graph |
| 12. | TigerGraph | graph |
| 13. | Fauna | multimodal |
| 14. | Giraph | graph |
| 15. | Dgraph | graph |
| 16. | AllegroGraph | multimodal |
| 17. | Blazegraph | multimodal |
| 18. | TypeDB | multimodal |
| 19. | Graph Engine | multimodal |
| 20. | SurrealDB | multimodal |
| 21. | InfiniteGraph | graph |
| 22. | FlockDB | graph |
| 23. | HyperGraphDB | graph |
| 24. | Fluree | graph |
| 25. | AnzoGraph DB | multimodal |
| 26. | Sparksee | graph |
| 27. | HugeGraph | graph |
| 28. | GraphBase | graph |
| 29. | ArcadeDB | multimodal |
| 30. | Bangdb | multimodal |
| 31. | RDFox | multimodal |
| 32. | Ultipa | graph |
| 33. | TinkerGraph | graph |
| 34. | TerminusDB | graph, multimodal |
| 35. | AgensGraph | multimodal |
| 36. | Galaxybase | graph |
| 37. | VelocityDB | multimodal |
| 38. | HGraphDB | graph |
| 39. | Transwarp StellarDB | graph |
Search Engines
If you need to search large amounts of data, especially unstructured data, it will be very useful to work with a database that would combine the functionality of text search with the functionality of information storage.
Let’s imagine that you have N petabytes of logs (or other text data). Ordinary word search is no longer suitable in this case.
Indexing is a great solution. If we consider it in a very exaggerated way, we can visualize it as follows: we assign an index to each word/term/n-gram and record these indices in a special table, where the rows are the document and the columns are the indices. A similar system is used for plagiarism search, but in this case shingles (indexes with layering) are used.
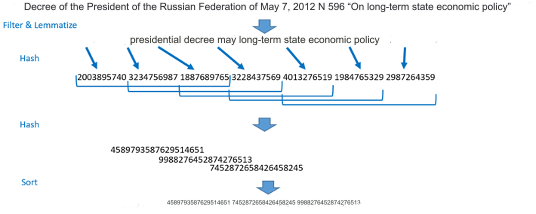
It is much faster to search by index than by matching words in the documents.
Of course, modern search engines offer wider functionality.
The most popular solutions of this kind are Elasticsearch (and its version – OpenSearch, Splunk (I wrote about it in one of the previous articles) and Sphinx.
Full list of search engines is given below:
| 1. | Elasticsearch | Search engine, multimodal |
| 2. | Splunk | Search engine |
| 3. | Solr | Search engine, multimodal |
| 4. | OpenSearch | Search engine, multimodal |
| 5. | MarkLogic | multimodal |
| 6. | Algolia | Search engine |
| 7. | Microsoft Azure Search | Search engine |
| 8. | Sphinx | Search engine |
| 9. | Virtuoso | multimodal |
| 10. | ArangoDB | multimodal |
| 11. | Coveo | Search engine |
| 12. | Amazon CloudSearch | Search engine |
| 13. | Meilisearch | Search engine |
| 14. | Xapian | Search engine |
| 15. | SearchBlox | Search engine |
| 16. | Typesense | Search engine |
| 17. | Vespa | multimodal |
| 18. | Marqo | Search engine |
| 19. | Alibaba Cloud Log Service | Search engine |
| 20. | Manticore Search | Search engine, multimodal |
| 21. | Exorbyte | Search engine |
| 22. | Tigris | мультимодальная |
| 23. | Indica | Search engine |
| 24. | Rizhiyi | Search engine, multimodal |
| 25. | searchxml | multimodal |
Object-oriented DBs
Object-oriented databases are databases where information is represented as objects, just like in object-oriented programming languages.
Object-oriented databases have appeared as a way of a code native communication which is written using object-oriented languages with a database.
Object-oriented databases have the following advantages:
- There is no problem of data model mismatch between the data model in the database and the application because the database stores the data in the same form;
- There is no need to maintain the data model on the database side separately;
- All the objects at the source level are strictly typed.
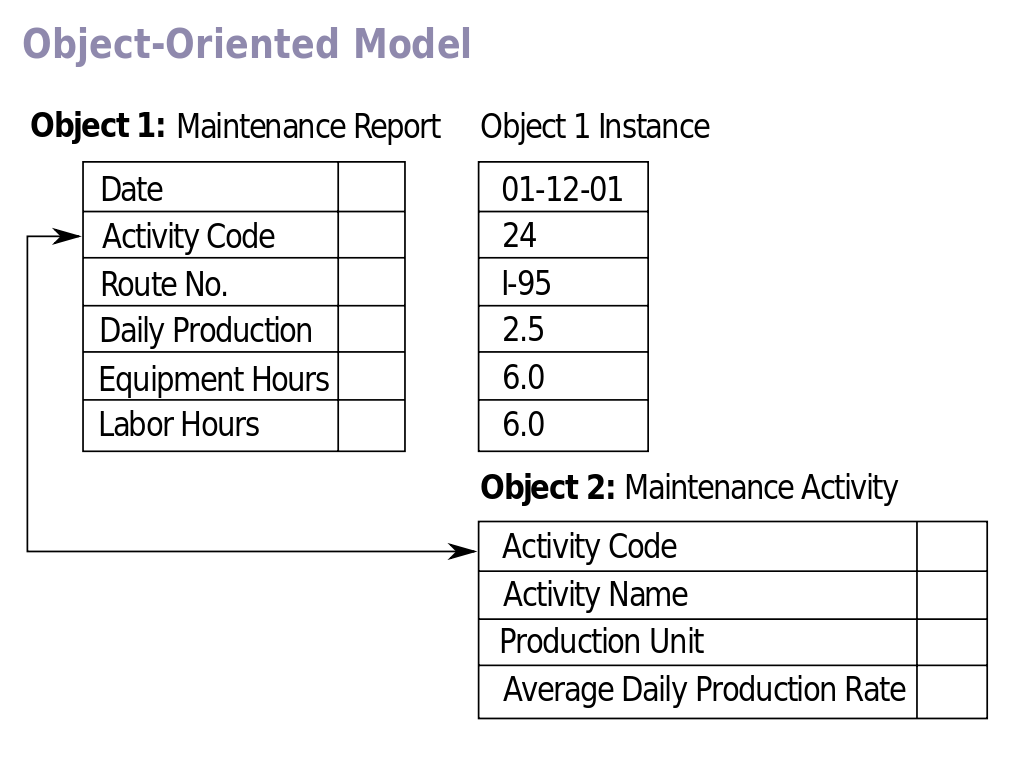
The best known object-oriented DBMS is Db4o.
Full list of these DBs is given below:
- InterSystems Caché – multimodal
- Db4o – object-oriented
- Actian NoSQL Database – object-oriented
- ObjectStore – object-oriented
- Matisse – object-oriented
- Perst – object-oriented
- GigaSpaces – multimodal
- ObjectBox – object-oriented, multimodal
- ObjectDB – object-oriented
- atoti – object-oriented
- GemStone/S – object-oriented
- Objectivity/DB – object-oriented
- Starcounter – object-oriented
- Jade – object-oriented
- Actian Fast – object-oriented
- Eloquera – object-oriented
- Siaqodb – object-oriented
- OrigoDB – multimodal
- DataFS – object-oriented, multimodal
- WakandaDB – object-oriented
- VelocityDB – multimodal
RDF (Resource Description Framework)
RDF databases are partly similar to graph databases. Their main function is based on the concept of formulating resource-related statements as subject-predicate-object expressions. The subject denotes the resource and the predicate denotes the features of the resource and defines the relationship between the subject and the object.
Here’s what Wikipedia says about RDF:
Resource Description Framework (RDF, “resource description framework”) is a model developed by the World Wide Web Consortium for representing data, especially metadata. RDF represents statements about resources in a form suitable for machine processing. RDF is part of the semantic web concept.
A resource in RDF can be any entity, whether informational (e.g. a website or an image) or non-informational (e.g. a person, a city or some abstract concept). A statement made about a resource has the form “subject – predicate – object” and is called a triplet. The statement “the sky is blue” in RDF terminology can be represented as follows: subject – “the sky”, predicate – “has a colour”, object – “blue”. URIs are used to denote subjects, relations and objects in RDF.

A set of RDF statements forms an oriented graph in which the vertices are subjects and objects and the edges represent relations.
RDF itself is not a file format, but an abstract data model, i.e. it describes the proposed structure, processing and interpretation of data. A number of record formats exist for storing and transmitting information stacked in the RDF model.
For processing RDF-data it is proposed to implement query languages such as SPARQL (W3C standard), RQL, RDQL.”
Full list of the DBs is given below:
- MarkLogic – multimodal
- Apache Jena TDB – RDF
- Virtuoso – multimodal
- GraphDB – multimodal
- Amazon Neptune – multimodal
- Stardog – multimodal
- AllegroGraph – multimodal
- Blazegraph – multimodal
- RDF4J – RDF
- Redland – RDF
- Strabon – RDF
- 4store – RDF
- Mulgara – RDF
- CubicWeb – RDF
- RedStore – RDF
- AnzoGraph DB – multimodal
- BrightstarDB – RDF
- Dydra – RDF
- RDFox – multimodal
- SparkleDB RDF
Wide Column Stores
Wide Column Stores is a NoSQL database that stores data in flexible columns that can be distributed across multiple servers or database nodes, using multidimensional mapping to reference data by column, row and timestamps.
The advantages of Wide Column Stores databases include query speed, scalability and a flexible data model.
The main difference in comparison with relational databases is the following:
A relational database management system stores data in a table with rows that span multiple columns. If one row requires an additional column, that column must be added to the entire table with NULL or default values for all other rows. If you need to query this DBMS table for a value that is not indexed, scanning the table to find these values will be extremely slow.
Wide Column DBMSs have the concept of rows like relational databases, but reading or writing a row of data consists of reading or writing individual columns. A column is written only if there is a data element for it. Each data item can be referenced by a row key, the value query is optimized in the same way as an index query in a DBMS.
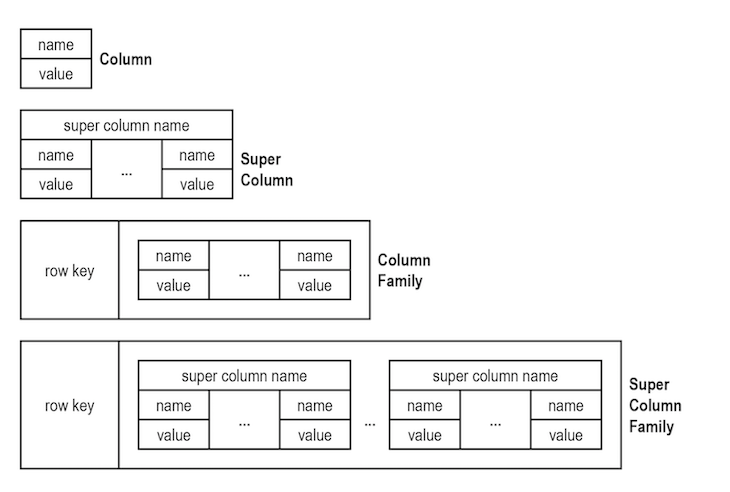
The first column model is an entity/attribute/value table. Inside each entity (columns) there is a table of values/attributes.
The Wide Column DBMS concept allows building solutions for processing really large amounts of data.
The most well-known implementations are Cassandra and HBase DBMSs.
Full list is given below:
- Cassandra – Wide column, multimodal
- HBase – Wide column
- Microsoft Azure Cosmos DB – Multimodal
- Datastax Enterprise – Wide column, multimodal
- ScyllaDB – Wide column, multimodal
- Microsoft Azure Table Storage – Wide column
- Google Cloud Bigtable – Multimodal
- HPE Ezmeral Data Fabric – multimodal
- Amazon Keyspaces – Wide column
- Elassandra – Wide column, multimodal
- Alibaba Cloud Table Store – Wide column
- SWC-DB – Wide column, multimodal
- Accumulo – Wide column
Multimodal DBMSs
It is worth saying that each multimodal DBMS can ultimately be reduced to one or more of the types on which they are based. Namely, it can be based on a relational model or on a document-oriented model etc. But they also allow emulating additional types in terms of user interaction with them.
Full list of the DBMSs is given below:
- Adabas – multimodal
- UniData – multimodal
- jBASE – multimodal
- Northgate Reality – multimodal
- Model 204 – multimodal
- D3 – multimodal
- SciDB – multimodal
- OpenInsight – multimodal
- Rasdaman – multimodal
- OpenQM – multimodal
Native XML DBMSs
The Native XML Database type is based on the use of internal XML representation in contrast to XML add-ons over existing relational databases (XML enabled DB), which implement XML-SQL according to the SQL-2003 access standard.
Native XML DBMSs are designed to manage a large number of XML documents.
XML native DB (NXD) uses an internal representation of the DOM XML in the database and has the following features:
- The minimal model includes: elements, attributes, PCDATA sections and document list;
- An XML document is represented as a fundamental part of the repository (like a table in a relational database);
- To access the XML native DB information store the XQuery query language should be used.
Full list of the Native XML DBMSs is given below:
- MarkLogic – multimodal
- Virtuoso – multimodal
- Oracle Berkeley DB – multimodal
- BaseX – Native XML
- Sedna – Native XML
- eXist-db – Native XML
- searchxml – multimodal
GEO/GIS and specialized DBMSs
If you are working at a map service or a specialized application that uses location data, it is logical to use a specialized DBMS.
Unlike other types of databases designed for processing numeric and symbolic information, spatial databases have the ability to work with complete spatial objects, combining both traditional and geometric types of data. Spatial databases allow us to perform analytical queries containing spatial operators for analyzing spatial and logical relations of objects (“intersects…”, “touches…”, “is contained in…”, “contains…”, “is at a given distance from…”, “coincides…” and others).
Full list of the DBMSs is given below:
- PostGIS – Spatial DBMS, multimodal
- Aerospike – multimodal
- SpatiaLite – Spatial DBMS, multimodal
- GeoMesa – Spatial DBMS
- H2GIS – Spatial DBMS, multimodal
- SpaceTime – Spatial DBMS, multimodal
Event DBMSs
Let’s imagine that the data in your DBMS has changed and you want to understand the event that changed it as well as to view the history of changes and what led to it.
Event databases store not only the data itself, but also the flow/sequence of its changes and the events that caused these changes.
This format can be useful both for incident investigation and for researching business and information processes occurring in an enterprise.
Here is a list of well-known event databases:
- EventStoreDB – Event
- NEventStore – Event
- IBM Db2 Event Store – multimodal
Content DBMSs
Content databases are the implementations of content repositories. They can be used to store and manage different content (photos, texts, code repositories, etc.).
Here are some examples of content databases:
- Jackrabbit – content
- ModeShape – content
Navigational DBMSs
Warning! Navigational databases have nothing to do with spatial databases. A navigational database is a type of database in which records or objects are found primarily by links from other objects. In some ways, it is close to the concept of graph databases.
A navigational database is a combination of a hierarchical and network model of database interfaces. Navigation methods use “pointers” and “paths” to navigate among the data records. The opposite model is the relational model, which uses “declarative” methods in which you ask the system what you want rather than how to get to it.
Here are some examples of navigational databases:
- IMS – navigational
- IDMS – navigational
Vector DBs
If you are engaged in machine learning, the main thing you have to work with is vectors. These can be rows from a table corresponding to the features of an object, or an embedding obtained at the output of a neural network that characterizes the processed object and is subsequently used for face identification or text translation.
Vector databases have been developed especially for this kind of tasks, allowing to work directly with vectors represented as numerical arrays.
The main advantage of such kind of the databases is the speed of search and processing of vectors.
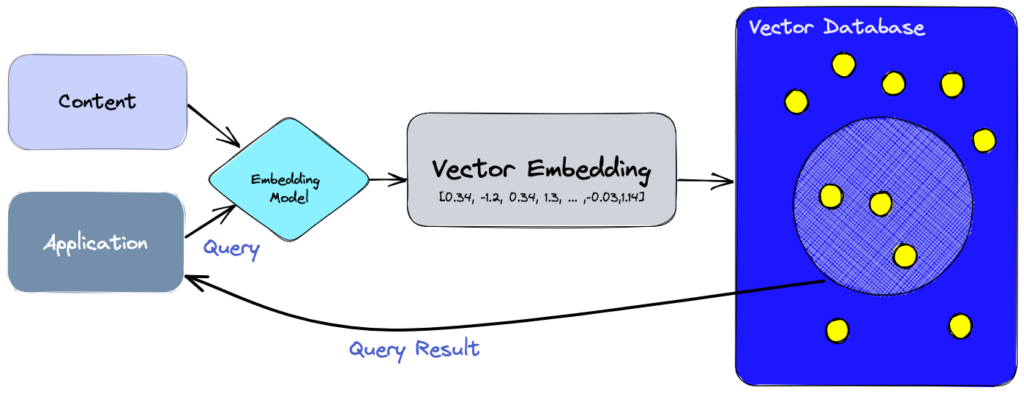
Vector databases are a relatively new type of DBMS, it is difficult to name a leader in this category.
List of the vector DBMSs:
- Kdb – multimodal
- Pinecone – vector
- Chroma – vector
- Milvus – vector
- Weaviate – vector
- Vald – vector
- Qdrant – vector
- Deep Lake – vector
- Vespa – multimodal
- MyScale – multimodal
Final thoughts
In this article we have looked through the different types of database management systems, starting from the most popular types, such as relational databases, and ending by the very exotic ones, such as navigational databases. Each type has its own specialization and purposes. The main purpose of the article was to give you a general idea of the variety of the existing DBMS, more details will be given later.